コードを書けないIT技術者
コードを書けないIT技術者。そんなにネガティブに見られることなのかね?
— 沢渡あまね新刊 #業務改善の問題地図 #ここアジャ #職場の科学 (@amane_sawatari) 2021年3月15日
経理で言えば「決算書を作ることはできないが、決算書を読むことができる/経営判断できる」人も価値ある訳で、要は価値の出し方の違いだと思うのよね。
勿論その組織が人材に何を求めるかにもよると思うけれども。
「IT技術者」という言葉の示す範囲が広く、個々人で受け取る範囲のイメージが異なりそうで、変なすれ違いが生まれそうだけど、こちらのツイートを自分が見たときには、「チームで取り組むので役割分担だし、そうだよね」と思う反面、「いや、コードを書けないとダメだろう」と思う自分がいる。 自分は、開発組織のマネージャーだったり、PMだったりを想像しながら、モヤモヤと考えていた。
そんな折に、寺田さん(@terapyon)のPodcastで以下のようなことが語られており、「これだわ」と思った。
だいたい1時間22分くらいのところからをテキスト化(とちょっと手直し)すると以下の内容になる。
建築現場の監督の人が、釘一本打てなくていいのかっていうものを思うわけです。遅いか早いか、色々あるので、そのプロとしていつもやってる人が早いからとか、綺麗だったりとかってあるけど、その概念知らなくていいのかっていうのがすごい思ってて。やらないと概念なかなかわかんないじゃないですか。
本業として日々書いている人ほど書けるように、とは思わないけど、やはり書いた経験(釘を打った経験)と、それに基づく概念の理解は必要だなと。沢渡さんの発言は理解できるものの、気持ちのうえでは書けてほしい、という思いが自分は強い。
Apple Trade Inを利用してみた
概要
Apple Trade Inを利用してみたので、その流れや悩んだことを書いてみる。詳しく紹介しているサイトが数多くあるので、詳細はそちらも参考にしていただければと思います。
下取り対象マシン
iMac i5 2.7GHz 21.5インチ(Late 2012)1TB HDD(下取り金額:15,000円)
全体の流れ
Appleでなにかを買う際にApple Trade Inを申し込み(申し込み忘れて買ってしまい、最初の注文をキャンセルした・・・)
↓
申し込み時に状態等を入力し、おおよその下取り額が決まる
↓
別途個人情報を入力するためのURLがメールで送られてくるので、入力し、身分証明書をアップロードする(健康保険証の番号を隠すなど、ちょっと面倒)
↓
集荷にくる前に下取り対象のマシンのフォーマットをする。こちらのページを参考に。
↓
集荷業者にPCを引き渡す(※ここで結構悩んだので、後述)
↓
査定結果がメールでくる
↓
クレカ払いだったので、クレカのほうで査定額分が戻ってくる
自分がとても悩んだポイント
iMacに付属していた、「キーボード」「トラックパッド」「電源ケーブル」を一緒に梱包してもらうのか?
ヤマトの人が集荷にきたので、聞いてみたところ「たぶん本体だけで大丈夫だと思いますが・・・」と不安げな回答。集荷用のボックス的にもキーボードやトラックパッドを集荷するスペースがないようだったので、ヤマトの人を信じて本体のみを集荷してもらった。
一方で、下のような記事もあり、梱包してもらうべきだったのか?と悶々としていた。
結論としては、「本体のみで、当初査定額が返金された」です。なので、キーボードやトラックパッドは別途売るか処分する必要があります。 調べていたときに下のブログも見つけていたので、余計に悩みました。結果、ヤマトの人が正解でした。
さいごに
「最悪、査定額が低くなってもいいか」と思いながらも、悶々としたので、イチ事例として共有して参考になればと思い書いてみました。
物欲に勝てない悪い存在(ただヘッドフォンが欲しいという話)
在宅ワークになり、色々とものを買っては使わず・・・という日々。 人間は欲深いもので、なにかを買って満たすと他に欲しい物が出てくる。
ガンディーが
所有するもの、欲しいと思うものが少なければ少ないほど、君はより良い存在となる。
と言っていますが、ダメですね。
というわけで、最近はなぜか「ヘッドフォン」に興味が。 在宅ワーク関係なく欲しくなったはずなのに、「仕事中に子どもがうるさいとき集中するのに、ノイズキャンセリングがあるとね・・・」とかなんとか理由を付けて買おうとする。
ノイズキャンセリングというだけで、ウン万円もするような高価なものには手を出せないので、比較的安価なもので調べていた。 見た目でいうと、こちらのソニーのが良かったのだけど、ノイズキャンセリング付いてなかったという・・・

結局これかなというのがAnkerさんの「Soundcore Life Q30」。ノイズキャンセリング付きで1万を切っており、音質も結構いいようで。Amazonのレビューを見るとケースのクレームが多いけど、ケースは別になんでもいいかなと思っているので、これを近々購入予定。

さてさて、次は何を欲するものやら・・・
入門Python3 第二版(読んでない段階での予告編)
Pythonを初めて学ぼうとしたときに、いくつか入門書があったのだけど、「漢たるものオライリーだ」という謎の理由で購入した「入門Python3」。
なんだかんだで、今でも基本的なことをど忘れしたときには開く。 その「入門Python3」の第二版。その名も「入門Python3 第2版」が発売された。
第一版も600ページとなかなかのボリュームだったのだけど、第二版はさらに充実して800ページ。ちょっとした鈍器になるボリューム。 第一版にお世話になった(ている)身としては、第二版も買おうかと思ったりするのだけど、厚い。悩ましい。
第一版がPython3.3(3.4)時代なので、第二版で対応したPython3.9では大きく進化がある。改めて読み直しても良いのかもしれない。が、厚い。
Python3.3 → 3.9で増えた内容
Wikipediaより抜粋。
自分の感覚だと、非同期系、f文字列、型ヒント、データクラス、あたりがパッと気にかかるポイント。第二版でこれらが充実していると嬉しい。手にとって見てみたいなぁ。やっぱり買うかなぁ。
3.4
- オブジェクト指向ファイルシステムパスを提供する「pathlib」モジュールの提供
- 列挙型を扱うためのenumモジュールの標準化
- 統計関数を提供するstatisticsモジュールの導入
- Pythonが割り当てたメモリブロックを追跡するためのデバッグツールのtracemallocモジュールの導入
- 非同期I/Oを扱うためのフレームワークとなるasyncioモジュールの導入
- Pythonの組み込み関数に関する分析情報を得るため機構の実装
3.5
- zipアプリケーションサポートの改良
- byte/bytearrayオブジェクトのための「%」フォーマット対応の追加
- 行列乗算演算子@の導入
- 高速ディレクトリトラバーサル機能os.scandir()の導入
- 割込がかかったシステムコールのオートリトライ機能追加
- 近似値であるかどうかをテストする機能の導入
- .pyoファイルの削除
- 拡張モジュールをロードするための新しい仕組みの導入
3.6
- 文字列中に式を埋め込める「Formatted string literals」の導入
- 変数に対して型に関する情報(型ヒント)を与える「Syntax for variable annotations」の導入
- 「async」および「await」文法 (async/await)でコルーチンを利用可能にする「Asynchronous generators」の導入
- 標準ライブラリにsecretsモジュールを追加
- DTraceおよびSystemTapプローブのサポートを追加
3.7
- 使用時点では宣言されていない型を使った型アノーテーション表記が可能となる
- レガシーな C ロケールの抑圧、強制 UTF-8 実行モード
- breakpoint() 関数の追加
- dict の挿入順の保存
- ナノ秒 (10-9 s) 単位の分解能を持つ新しい時間関数の追加
- コンテキスト変数
- データクラス
3.8
- 代入式 :=
- 位置のみのパラメータ
- f文字列で f'{expr=}' の形式のサポート
- pickle プロトコル5
- dict での reversed のサポート
※3.9の追加分がまだまとめられていなかった・・・
寺田さんが以前にPodcastで3.9の変更点について語っていたので、参考にリンクを貼っておきます。
【Mac】Macのアプリ「Shiftlt」が便利な予感
まえがき
数年も前の話だけど、仕事のマシンをWindowsからMacに乗り換えたときに、「Windows + ←」や「Windows + →」が使えないことに衝撃を受けた。Exccelファイルを画面の左と右に並べたり、なんてことを昔はしていたので。 よくよく思い返すと、仕事でMacを使うようになったときには、そのニーズなかったな、とか思ってしまったけど、「Shiftlt」を見つけた(今更)感動を記しておきたい。 (なぜかわからないが、変なテンションで書いてしまった)
Shiftltとは?
Macのウィンドウを左半分、下半分、などできるアプリ。Mac標準でも左半分、右半分はできるのだけど、上や下はできない。ショートカットもない。 しかし、Shiftltならそれらができる。そう、できる。
入れてみよう
ダウンロード
Releases · fikovnik/ShiftIt · GitHub
こちらから「zip」をポチッと。2021年3月19日時点だと「1.6.6」が最新。

解凍して「アプリケーション」にドロップ
起動前のちょい設定 & 起動
「アプリケーション」フォルダで、「control」押しながらダブルクリックすると、開いても良いか聞かれるので「開く」を押す。
「システム環境設定を開く」を選択して進む。「アクセシビリティ」で左下の鍵マークを選択して、パスワードを入れたら「Shiftlt」のチェックをつける。
その後は普通にアプリケーションを開くと自動的に開くか聞かれるので、お好みで選択。自分はもちろん?「はい」を選択。
上部のバーに、
 が表示されればOK。
が表示されればOK。
あとはショートカットを参考にしながらウィンドウを自由自在にコントロール! (ちょっとショートカットキーが押しにくい配置だが・・・)
Python3.9をHomebrewでM1 Macにインストールする(2021年3月16日時点)
概要
機器を入れ替えてイチからPythonをインストールする機会に恵まれたので、記録を残す。思いの外、参考リンクの通りにいかないのが世の常。
参考リンク
対象機器
MacBook Air(M1, 2020) macOS Big Sur(11.2)
インストール手順詳細
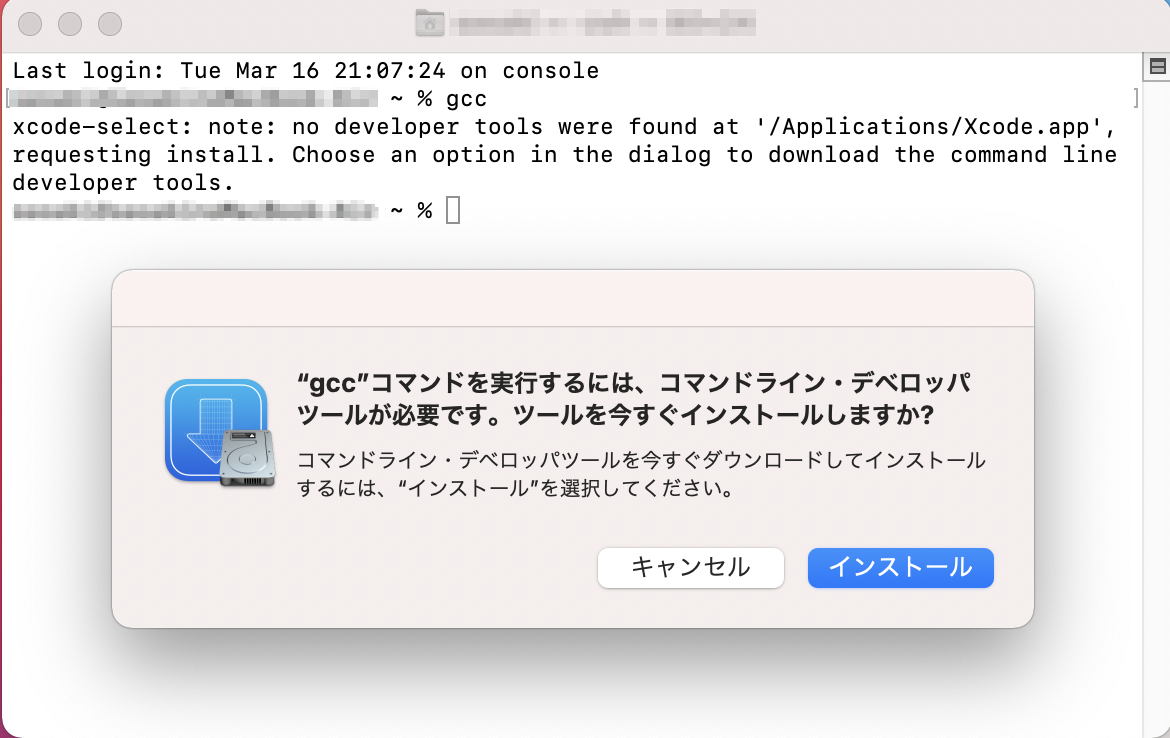
Command Line Toolsのインストール
手順通り以下のコマンドを実行すると、Command Line Toolsをインストールするように言われるので、言われるがままにインストール。
$ gcc
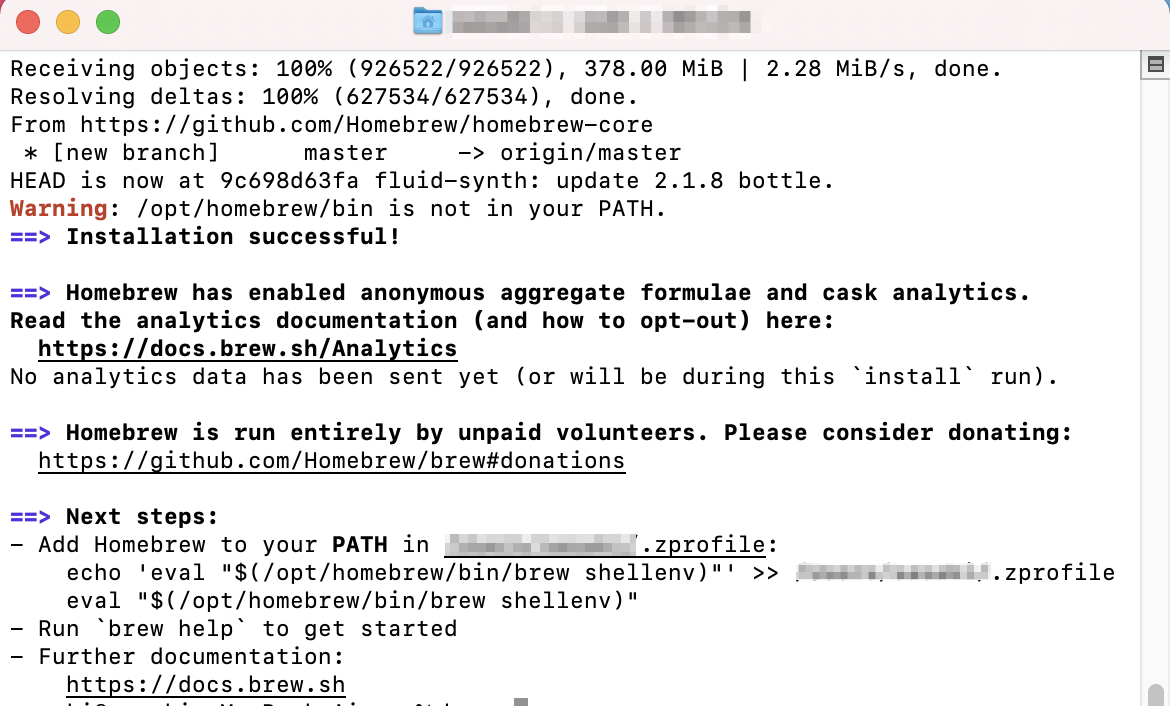
Homebrewのインストール
以下のコマンドを打ちます。手順に従い、なすがままです。
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
最後のログはこんな感じです。
以下のコマンドを打ってzshのプロファイルに登録します。実際のコマンドは、自身のターミナルに表示された内容で置き換えてください。
$ echo 'eval "$(/opt/homebrew/bin/brew shellenv)"' >> /Users/******/.zprofile
試しに、
brew help
と打って、brewのヘルプが表示されれば成功です。
Pythonをインストール
$ brew search python
すると、以下のように表示されます。3.7以降がインストール可能なようです。
==> Formulae app-engine-python gst-python python-markdown python@3.8 boost-python ipython python-tabulate python@3.9 boost-python3 micropython python-yq reorder-python-imports bpython ptpython python@3.7 wxpython ==> Casks homebrew/cask/awips-python homebrew/cask/kk7ds-python-runtime homebrew/cask/mysql-connector-python
特段、古いのにこだわりがあるわけではなかったので、最新を入れます。
brew install python3
と思ったら騙されました。これだとPython3.8がインストールされました。
$ python3 -V Python 3.8.2
むむ、python3.9はどこに?というわけで探します。
$ which python3.9 /opt/homebrew/bin/python3.9
python3の場所を探して、シンボリックリンクを貼って、python3コマンドで、python3.9が動くようにしておきます。
$ which python3 /usr/bin/python3
$ sudo ln -s /opt/homebrew/bin/python3.9 /usr/bin/python3 ln: /usr/bin/python3: Operation not permitted
おろ・・・許可されてないと怒られた。調べてみると、以下の記事にあるように「/usr/bin/」への変更はroot権限でも許可されてないようです(初心者ですみません)。
初心者向け MacでOperation not permittedの解決方法 - Qiita
さらに調べてみたところ、.zprofileにパスを通してあげれば、「python」コマンドで最新のpythonを動かせるようだったので、以下の通り「.zprofile」を修正しました。2行目の「export〜」を追記しています。
$ vim ~/.zprofile
eval "$(/opt/homebrew/bin/brew shellenv)" export PATH=/opt/homebrew/opt/python@3.9/libexec/bin:$PATH
これで、晴れてpythonコマンドで最新のpythonが動くように変更できました。
$ python -V Python 3.9.2
python3.10が出たときも、brewでインストールしたあとに、同様に.zprofileを修正してパスを通せばOKそうです。
余談
今回は「.zprofile」に足しました。シェルの設定系は苦手だったので、以下の記事も参考にしました。
zshの設定ファイルの読み込み順序と使い方Tipsまとめ - Qiita
zshrcとzprofileについて - gallardo diary
あとはこちらの記事も参考にさせていただきました。ありがとうございました。
子育てって障害対応みたいだな
この例えを同僚にしたときには、「やめてー」と言われたのだけど、自分的には結構しっくりくるので書いてみます。 なんとなくの対象読者は、「システム運用/保守経験があって、子育てをしたことがなくて、子育ての大変さを理解したい人」です。ニッチだ。
色々誤解を与えないために
どのくらい大変かを例えてみただけです。他意はないです。控えめに言って、子どもはめちゃかわいいです。
伝えたいこと
子育て(特に乳児)は、「命に係わるような対応マストの大障害が2~3時間おきに発生しうる日々が24時間365日続き、なおかつ対応メンバーは2人。もちろん障害対応だけやっていればいいわけではなく日中も別の業務がある」という状況です。あー、大変。
対応マストの障害
システム(子ども)にもよるんですが、だいたい2~3時間おき(短いときは1時間おき)に、社用携帯が鳴ります。嘘です。子どもが泣きます。 自然復旧することはないシステムなので、何かしらの初動が必要です。おむつを替えたりミルクをあげたり。自動化なんてナウいことはできません。
サービスイン(生まれた)直後は、昼とか夜とかの概念がなく障害が発生します。しばらくすると安定稼働し始め、社用携帯が鳴る頻度はもう少し減ります。相変わらず自然復旧はしないのですが。
対応メンバー
チーム(家庭)にもよるのですが、基本的なメンバーは2人(夫婦)です。チームによっては1人の場合もありうるし、2人のチームだけど片方のメンバーが協力的でないなどもありえます。チームの体制が薄くて辛くても訴えかけるマネージャーはいません。ただ、チームによっては増員(親兄弟や知人、家政婦など)もできなくはないです。 障害対応もチームの方針によってはおおきく属人化が発生します。例えば空腹時。「母乳だけでいくのだ!」というチームの場合は、「お腹が空いた」という障害対応にメンバーの1人(夫)は参加できません。属人化した対応に、無力感を味わうしかないです。
日中の別業務
限られたメンバーでギリギリがんばりますが、もちろん業務調整をしてくれるマネージャーはいません。どれだけ夜間対応が辛くても、日中の業務はそれとしてこなさなければいけません。炊事・洗濯・掃除・洗い物・ etc...。とてもブラックです。 ただ、コストさえ許せば日中の業務はいくらか自動化などの余地はあります。乾燥機、食洗器、ルンバ、などなど。文明の発展に感謝の気持ちを持ちながら、投資をします。 あとは、保守しているシステム(子ども)が1つであれば、メンバー間の話し合いによりタスクの簡略化は可能です。「ごはんは適当でいいか~」など。ただ、2つ以上のシステムだと、手を抜けないものが増えます。
おわりに
特段オチもない感じではあるけれど、夜間の障害対応を経験した人であれば、雰囲気がわかってもらえるのではないかと思います。 ちなみに、前述した通りサービスインしてからしばらくすると、システムも安定してきて夜間の障害対応も減ります。ただ、中長期を見据えて対応しなくてはいけない課題(将来の進路がどうとか)が出てきたり、逆に安定して手がかからなくなって寂しくなったりするようです。自分の場合はまだそこまで安定してないです。